
Classification
We are no longer trying to predict a real value like linear regression. For classification problems we are trying to predict 0 or 1 (discrete values). Example: spam or not spam, benign or malignant tumor etc. For Linear regression, we have HΘ(X) =ΘTX = real number (R) R can be <= 0 or >= 1 which is strange if we used the same model for classification problems. As y should be ∈ {0, 1}. We will use logistics regression for classification problems.
Hypothesis Representation
The H function for Logistics regression is HΘ(X) = G(H of linear regression) = G (ΘTX) = 1 / (1 + e-0TX)
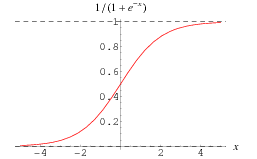
HΘ(X) =1 / (1 + e-0TX) –> known as sigmoid or logistics function.
From the plot, we see that 1 / (1 + e-0TX) produce an output 0 to 1. The output can be treated as a probability value.
Decision Boundary
The line which separate the region which predicts y = 0 from y = 1.
From the plot of the sigmoid function , we see that
if input value (X) to sigmoid is >= 0 , then 0.5 <= HΘ(X) <= 1
if input value (X) to sigmoid is < 0 , then 0 <= HΘ(X) < 0.5
P(y = 1 | X; Θ) = 1 whenever HΘ(X) >= 0.5 and X >=0
P(y = 0 | X; Θ) = 0 whenever HΘ(X) < 0.5 and X < 0
Decision boundary is the result of the chosen theta and not of the data set.
Cost function of Logistics Regression
Suppose we used the cost function of linear regression for logistics regression, the function will be non-convex plot due to non-linear property of the sigmoid function. Non-convex property will not allow us to have a global optimal.
J(Θ) =1/2m * m∑i=1(HΘ(Xi) – yi)2 —-> linear regression’s cost function , if we substitute H function with the sigmoid function, this function become non-convex. Therefore we need another model.
Cost of Logistics Regression
Cost(HΘ(X), y) = {
-log(HΘ(X)) if y = 1
-log(1 – HΘ(X)) if y = 0
}
Interpretation
First we know HΘ(X) = 1/(1 + e-0TX) = real number (r) , therefore
if y = 1 , the cost would be = -log(r)
if y = 0 , the cost would be = -log(1 – r)
Why it works ?
We know the output of sigmoid is between 0 and 1.
If y = 1 and we predicted as 0 , the cost would shoot up and vice versa. If the cost is high due to wrong prediction, it means the choice of theta is bad which mean the penalty is justified. This function has the convex property too.
Simplified Cost Function
Cost(HΘ(X), y) = – y log(HΘ(X)) – (1 – y) log (1 – HΘ(X))
Therefore we have
J(Θ) = -1/m * [ m∑i=1 yi log(HΘ(xi )) + (1 – yi ) log (1 – HΘ(xi ))]
Gradient Descent
The update rule looks the same as linear regression. However do take note the definition of HΘ is now the sigmoid function of 1 / (1 + e-0TX) and not ΘTX. The goal of minimizing the cost with the optimal choice of theta is still same.
repeat {
Θj = Θj – alpha * [1/m * m∑i=1(HΘ(Xi) – yi) * jXi ] –> simultaneous update for Θj for j = 0 to n
}
[1/m * m∑i=1(HΘ(Xi) – yi) * jXi ] –> derivative term which output the gradient
Optimization
There exists other methods to minimize cost function without needing for us to choose alpha (learning rate). Octave provide fminunc (minimum unconstrain) function which is described as gradient descent on steroids. Looks like a high level order function which take a function(G) , initial theta vector and option vector. Function G should return a cost and a gradient vector and give it to fminunc to compute. Options will indicate the number of iterations etc.
Gradient vector[0] = [1/m * m∑i=1(HΘ(Xi) – yi) * 0Xi]
Gradient vector[1] = [1/m * m∑i=1(HΘ(Xi) – yi) * 1Xi]
.
.
Gradient vector[n] = [1/m * m∑i=1(HΘ(Xi) – yi) * nXi]
Note: We did not pass in the learning rate alpha to fminunc.
Multiclass Classification: One vs all
Idea is take n classes and convert it to n separate 2 class classification problem.
Suppose we want to classify or predict if a person falls into which of the following groups based on some features.
friend, lover, relatives, foe
We ask separately
1. If he/she is a friend (Yes/No) –> Classifier1 1HΘ(x)
2. If he/she is a lover (Yes/No) –> Classifier1 2HΘ(x)
3. If he/she a relative (Yes/No) –> Classifier3 3HΘ(x)
4. If he/she our enemy (Yes/No) –> Classifier4 4HΘ(x)
4 Hypothesis with each Hypothesis predicting a 1 or 0 value

{kind=link}